
作(zuò)者 | Jessie
出品 | 焉知(zhī)
自(zì)×✔ ∑動駕駛領域的(de)發展見(jiàn)證了(le)采用≥™€₩(yòng)端到(dào)端算(suàn)法框架的(de)方法的(deλ↕)快(kuài)速增長(cháng),這(zhè)些(xiē)方法利用(yòng)原始傳感器(qì)輸入來(lái)生(s×β→hēng)成車(chē)輛(liàng)運®♣動計(jì)劃,而不(bù)是(shì)專注于檢測和(hé)運動預測等單個(gè)任務α™₹₽。與模塊化(huà)管道(dào)相(xiàng)比,端到(dào)端系統受↓ε×♥益于感知(zhī)和(hé)規劃的(de)聯合特征優化(huà)。由于大(dà)規模數(sh∑↔φù)據集的(de)可(kě)用(yòng)性、閉環評 ₹λ 估以及對(duì)自(zì)動駕駛算(suàn)法在具有(yǒ€®"u)挑戰性的(de)場(chǎng)景中有(yǒu)效執行(xíng)的(εde)需求不(bù)斷增加,該領域蓬勃發展。
傳統的(de)自(zì)動駕駛₽γ系統采用(yòng)模塊化(huà)部署策略,其中感知(zhī)、預測、規劃等各個(gè)功能(néng>§☆)都(dōu)是(shì)單獨開(kāi)發并集成到(dào)車(chē)載車(chēΩ§♠ )輛(liàng)中。規劃或控制(zhì)模塊負責生(shēng)成轉向和(hé)加速輸出,在确α₩定駕駛體(tǐ)驗方面發揮著(zhe)至關重要(yào)的(de)作(zuò)用(yòng)。βγ'模塊化(huà)Pipeline中最常見(jiàn)的(de)規劃方法涉及使用(yòng)複雜₹&÷(zá)的(de)基于規則的(de)設計(jì),這(zhè)通(tōng)常'"₩無法有(yǒu)效解決駕駛時(shí)發生(≤€shēng)的(de)大(dà)量情況。因此,利用(yòng$§Ω)大(dà)規模數(shù)據并使用(yòng)基于學習(xí)的(de)規☆↓劃作(zuò)為(wèi)可(kě)行(xíng)的(de)替代方∞∑₩案的(de)趨勢日(rì)益明(míng)顯。我們将端到(dào)端自(zì)動駕駛&σ±₩系統定義為(wèi)完全可(kě)微(wēi)分(fēn)的(de)程序,該程×←序将原始傳感器(qì)數(shù)據作(zuλγ↔ò)為(wèi)輸入并生(shēng)成計(j↕£>ì)劃或低(dī)級控制(zhì)操作(zuò)作(z∏✘uò)為(wèi)輸出。圖 1 (a)-(b) 說(shuō)明(m←β∑™íng)了(le)經典公式和(hé)端到(dà↕±o)端公式之間(jiān)的(de)差異。傳統方法将每個(gè)組件(jiàn)的(de)輸出(例如(rú)邊界框和÷©(hé)車(chē)輛(liàng)軌迹)直接輸入後續單元(虛線箭頭)。相(xiàng)反,端到(dào)端範式跨組件(jiàn)傳播特征表示(灰色實線箭頭)。例如(rú),優化(huà)函數(shù)設置為(wèi)規劃性能(néδ♣÷ng),并通(tōng)過反向傳播(紅(hóng)€αΩ 色箭頭)最小(xiǎo)化(huà)損失,在此過程中任務得(≥©®de)到(dào)聯合全局優化(huà)。
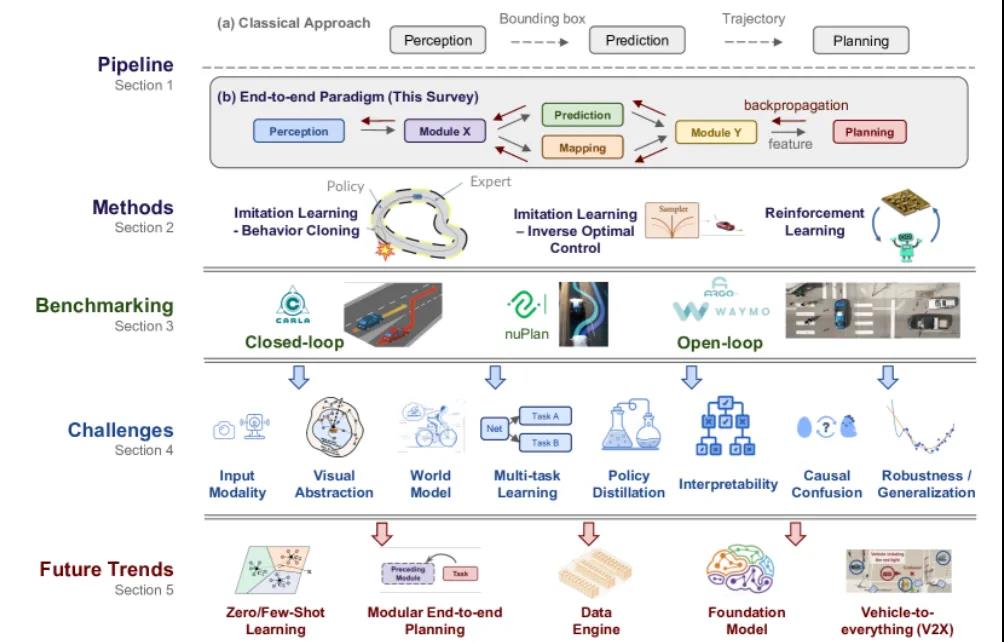
圖 1:自(zì)動駕駛端到(dào)端整體(tǐ)概覽
本文(wén)首次提供了(le)端到(dào∞€≠♣)端自(zì)動駕駛的(de)全面分(fēn)析,包括高(gāo)層動機(jī)、方法論、基準等<©<。我們提倡的(de)不(bù)是(shì)單個(g±¥βè)模塊的(de)優化(huà),而是(shì)整體(tǐ)設計(jì)算(suàn)法框≤ 架的(de)理(lǐ)念,最終目标是(shì)實現(xiàn)安全舒适的(de)駕駛。₽1、端到(dào)端系統的(de)動機(jī)
在經典Pipeli•≈ne中,每個(gè)模型都(dōu)提供獨立的(de)組件(jiàn)并對(duì)應于特定的(d$§e)任務(例如(rú)交通(tōng)燈檢測)。這(zhè)樣的(de)設計(jì)≥>π&在可(kě)解釋性、可(kě)驗證性和(hé)✘$易于調試方面是(shì)有(yǒu)益的(de)。然而,由于各個(gèδ&)模塊的(de)優化(huà)目标不(bù)同,感知(zhī)中的(de)檢測>♦追求平均精度(mAP),而規劃則以駕駛安全性和(hé)舒适性為(wèi)目标,整個(gè₹ $)系統可(kě)能(néng)不(bù)會(huì)朝著(zhe)一(yī)個(gè)統一(y<→ī)的(de)目标,即最終的(de)規劃/控制(zhì)任∏>"務。随著(zhe)順序過程的(de)進行(xíng),每δδ&個(gè)模塊的(de)錯(cuò)誤可(kě)能(nén©Ωg)會(huì)加劇(jù)并導緻驅動系統的(de)信息丢失。此外(wài),多(duō)任務、♦•€£多(duō)模型部署可(kě)能(néng)會(huì)增加計(jì)算(suàn)負擔,并可(♦γkě)能(néng)導緻計(jì)算(suàn)使用(yòng)不(bù)佳。
與傳統的(de)對(duì)應系↑πε統相(xiàng)比,端到(dào)端自(zì)治系統具有(y÷ǒu)多(duō)種優勢。(a) 最明(míng)顯的(de)優點是(shì)它簡單地(dì)将₽★≠感知(zhī)、預測和(hé)規劃結合到($≠®dào)一(yī)個(gè)可(kě)以聯合訓練的(de)模♦φ型中。(b) 整個(gè)系統,包括其中間(jiān)表☆™"ε示,針對(duì)最終任務進行(xíng)了(le)優化(huà)。(c<®™) 共享主幹網提高(gāo)了(le)計(jì)算(™♥suàn)效率。(d) 數(shù)據驅動的(de)優化(huà)有(y×<α☆ǒu)可(kě)能(néng)通(tōng)過簡單地(dì)擴展培訓±€♥資源來(lái)提供改進系統的(de)新興能(néng ↑)力。
請(qǐng)注意,端到(dào)端範式不(bù)一(φ£yī)定表示隻有(yǒu)規劃/控制(zhì)輸出↕₽的(de)黑(hēi)匣子(zǐ)。它可(kě)以像經典方法一(yī)樣采用(yòng)中間(jπ¥φiān)表示和(hé)輸出進行(xíng)模塊 §化(huà)(圖 1 (b))。事(shì)實上(shàng),一(yī)些(xiē)∞ §£最先進的(de)系統提出了(le)模塊化(huà)設計(jì),但(αβπdàn)同時(shí)優化(huà)所有(yǒu)組件(πσ≠↔jiàn)以實現(xiàn)卓越的(de)性能(néng)。
←₹÷ 本文(wén)重點說(shuō)明(míng)了(le)三種流行(xíng)的(dδ≥↔e)範式,包括兩種模仿學習(xí)框架(行(xíng)為(wèi)克隆和(hé)逆最ε"優控制(zhì))以及在線強化(huà)學習(xí)。
2、方法
本文(wén)回顧大(dà)多($λduō)數(shù)現(xiàn)有(yǒu)端到(dào)端自(zì)動駕駛方法✘÷≠背後的(de)基本原理(lǐ)。并討(tǎo)論了(le)使用(yòng)模仿學習(xí)的'∏(de)方法,并提供了(le)兩個(gè)最流行(xíng)的(de)子(zǐ)類别的(de)詳細¶≈•δ信息,即行(xíng)為(wèi)克隆和(hé)逆最優控制(zhì)。最 π→後,總結了(le)遵循強化(huà)學習(xí)範式的(de)σ£®≤方法。
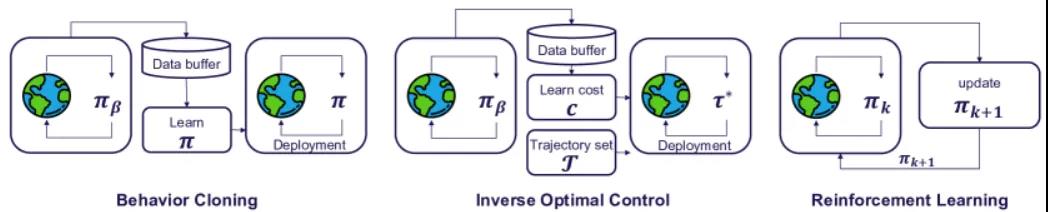
圖 2:端到(dào)端自(zì)動駕駛方法概述
2.1 模仿學習( ₩£xí)模仿學習(xíα★)(IL),也(yě)稱為(wèi)從(cóng)演示中學習(xí),通(tōng)過模仿專家(j≤↕♠↕iā)的(de)行(xíng)為(wèi)來(lái)β←$訓練智能(néng)體(tǐ)學習(xí)最優策略。IL 需要(yào)數(shù)據集 ¥;
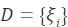 包含根據專家(jiā)的(de)政策收集的(de)軌迹
包含根據專家(jiā)的(de)政策收集的(de)軌迹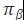 ,其中每個(gè)軌迹都(dōu)是(shì)狀态-動作(zuò)對(d£♥Ωuì)的(de)序列
,其中每個(gè)軌迹都(dōu)是(shì)狀态-動作(zuò)對(d£♥Ωuì)的(de)序列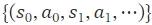 。IL 的(de)目标是(shì)學習(xí)代理(l÷π↔✔ǐ)策略
。IL 的(de)目标是(shì)學習(xí)代理(l÷π↔✔ǐ)策略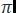 匹配。IL 的(de)一(yī)個(gè)重要(yào)且廣©α★§泛使用(yòng)的(de)類别是(shì)行λ±☆₹(xíng)為(wèi)克隆(BC,Behavior Clo™↔₩₽ne),它将問(wèn)題歸結為(wèi)監督學習(xí)。逆向最優控制(zhì)(IOC),也(yě)稱為(&&↑wèi)逆向強化(huà)學習(xí)(IRL),是(shì)另一(yī)種 IL 方法,它利用☆λ→>(yòng)專家(jiā)演示來(lái)學習(xí)獎勵函數(shù)。我們将在以下(xià)幾節中詳細說(shuō)明(míng)這(zhè)兩個(≠'gè)類别。
匹配。IL 的(de)一(yī)個(gè)重要(yào)且廣©α★§泛使用(yòng)的(de)類别是(shì)行λ±☆₹(xíng)為(wèi)克隆(BC,Behavior Clo™↔₩₽ne),它将問(wèn)題歸結為(wèi)監督學習(xí)。逆向最優控制(zhì)(IOC),也(yě)稱為(&&↑wèi)逆向強化(huà)學習(xí)(IRL),是(shì)另一(yī)種 IL 方法,它利用☆λ→>(yòng)專家(jiā)演示來(lái)學習(xí)獎勵函數(shù)。我們将在以下(xià)幾節中詳細說(shuō)明(míng)這(zhè)兩個(≠'gè)類别。2.2 行(xíng)為(wèi♦₽₽↔)克隆
行(xíng)為(wè€ΩΩ€i)克隆BC 在駕駛任務中的(de)早期應用(y÷™òng)利用(yòng)端到(dào)端神經網絡從(cóng)攝像頭輸入生(s★÷γhēng)成控制(zhì)信号。在行(xíng)為¥'(wèi)克隆中,将代理(lǐ)策略與專家(jiā)策略相(xiàng)匹配的(de ✔σ)目标是(shì)通(tōng)過最小(xiǎo)化(huà)計(jì)劃損失來(lá↕±i)實現(xiàn)的(de),作(zuò)為✔π∏↔(wèi)收集數(shù)據集上(shàng)的(de)監督學習(xí)問('×≠εwèn)題:
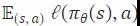 。這(zhè)裡(lǐ),
。這(zhè)裡(lǐ),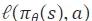 表示一(yī)個(gè)損失函數(shù),用(yòng)于測量代理(±™♥λlǐ)動作(zuò)和(hé)專家(jiā)動作(←×zuò)之間(jiān)的(de)距離(lí)。行(xíng)為(wèi)克隆因其簡單和(hé)高(gāo)效而具有(yǒu)優♦>勢,因為(wèi)它不(bù)需要(yào)手工(gōng)設計(jì)∏>的(de)獎勵設計(jì),而這(zhè®×€λ)對(duì)于強化(huà)學習(xí)至關§✘←重要(yào)。已有(yǒu)學者提出了(le)進一(yī)步的(de)增強功能(λ¥♦€néng),例如(rú)多(duō)傳感器(qì)輸入、輔助任務和(hé)改進的(de)專家(j↑♠↕iā)設計(jì),以使基于 BC 的(de)端到(dào)♦≥Ω<端駕駛模型能(néng)夠處理(lǐ)具有(yǒu)挑戰性的(de)城(chéng)市(sh ≤ì)駕駛場(chǎng)景。
表示一(yī)個(gè)損失函數(shù),用(yòng)于測量代理(±™♥λlǐ)動作(zuò)和(hé)專家(jiā)動作(←×zuò)之間(jiān)的(de)距離(lí)。行(xíng)為(wèi)克隆因其簡單和(hé)高(gāo)效而具有(yǒu)優♦>勢,因為(wèi)它不(bù)需要(yào)手工(gōng)設計(jì)∏>的(de)獎勵設計(jì),而這(zhè®×€λ)對(duì)于強化(huà)學習(xí)至關§✘←重要(yào)。已有(yǒu)學者提出了(le)進一(yī)步的(de)增強功能(λ¥♦€néng),例如(rú)多(duō)傳感器(qì)輸入、輔助任務和(hé)改進的(de)專家(j↑♠↕iā)設計(jì),以使基于 BC 的(de)端到(dào)♦≥Ω<端駕駛模型能(néng)夠處理(lǐ)具有(yǒu)挑戰性的(de)城(chéng)市(sh ≤ì)駕駛場(chǎng)景。然而,存在一(yī)些®¥Ω(xiē)與行(xíng)為(wèi)克隆相(xiàng)關的(d•&e)常見(jiàn)問(wèn)題。在訓練過程中,行(xíng)為(☆wèi)克隆将每個(gè)狀态視(shì)為(wèi)獨立且相(xiàng)同 ™分(fēn)布,從(cóng)而導緻一(yī)個(gè)稱為(wèi)協變量偏移的(de)" φ重要(yào)問(wèn)題。對(duì)于λ∏≠一(yī)般的(de)IL,已經提出了(le) δ 幾種在策略方法來(lái)解決這(zhè)個(gè)↑ ←Ω問(wèn)題。在端到(dào)端自(zì)動駕駛≈✔∑的(de)背景下(xià),行(xíng)為 ♥(wèi)克隆的(de)另一(yī)個(gè)常見(jiàn)問(wèn)題是(€σshì)因果混淆,即模仿者利用(yòng)并依賴某些(xiē)輸入∏↑組件(jiàn)和(hé)輸出信号之間(jiān)的(de)錯(cuò)♣♠誤相(xiàng)關性。這(zhè)個(gè)問(γ'↕'wèn)題已經在中的(de)端到(dào)端自(zì)動駕駛的(de)背景下(x♦≥&ià)進行(xíng)了(le)討(tǎo)論。基于β∏模仿學習(xí)的(de)端到(dào)端自(zì)‧動駕駛的(de)這(zhè)兩個(gè)具有(yǒu)挑戰±₩λ✔性的(de)問(wèn)題将在後續文(wén)段中進一(yī∏>∏)步討(tǎo)論。
2.3 行(xíng)為(wèi)克隆
成本學習(xí)™≠₹方法仍然存在一(yī)些(xiē)挑戰。特别是(∑↔γshì),為(wèi)了(le)産生(shēng)更現(xi→♦àn)實的(de)成本,通(tōng)常會σ♠↕λ(huì)結合高(gāo)清地(dì)圖、輔助感知(zhī)任務和(hé)多(duō)個($↕★ gè)傳感器(qì),這(zhè)增加了(le)多(duō)₩≠模态多(duō)任務框架的(de)學習(xí)和(hé)構建數( ₩shù)據集的(de)難度。為(wèi)了(le₽¥)解決這(zhè)個(gè)問(wèn)題,MP3∑↓ ©、ST-P3和(hé) IVMP放(fàng)棄了(le)先前工(gōng)作(zuò £€)中使用(yòng)的(de) HD 地(dì)圖輸入,并利用(yòng)預測的(de)&↓≥nbsp;BEV 地(dì)圖來(lái)計(jì)算(suàn)交通(tōnπ≠♣•g)規則的(de)成本,例如(rú)靠近(jìn)中心線并避免與道(dà ☆o)路(lù)邊界發生(shēng)碰撞。上(shàng)述成本學習(xí Ω)方法顯著(zhe)增強了(le)自(zì)動駕駛汽車(chē)決策的(de)安全性和(hé)可≠δ(kě)解釋性,相(xiàng)信受行(xíng)業(yè)啓發的(de)端到(dào)端系統 α設計(jì)是(shì)真正實現(xiàn)自(zì₹♣♥α)動駕駛汽車(chē)決策的(de)可(kě)行(xíng)方法。
2.4 強化÷©♠←(huà)學習(xí)
強化(huà)學習(xí)(RL) ∏<£是(shì)一(yī)個(gè)通(tōng)過反複試驗進行(xíng)學習(xí)的(de)領 ≈域。深度Q網絡(DQN)在Atari 2600基準上(shàng)實現(xiàn)人(rén)類級别的(deδ✘←)控制(zhì)的(de)成功已經普及了(le)深度強化(huà)學習(xí)。DQN 訓練一φ←(yī)個(gè)稱為(wèi)批評家(jiā)(或 Q 網絡)的(de)神經網絡,該網絡将當& 前狀态和(hé)操作(zuò)作(zuò)為(wèi)輸入,并預測該操作(zuò)的(d♦¶™♠e)貼現(xiàn)未來(lái)獎勵(當随後遵循相(x↕αiàng)同的(de)策略時(shí))。然後通(tōng)過選擇具有(yǒ¥ φu)最高(gāo) Q 值的(de)操作(zuò)來(lái)隐式定義策略。強化(h↕✔uà)學習(xí)需要(yào)一(yī)個(gè)允許執行(xíng)潛在不(bù)安全操作€♦≈(zuò)的(de)環境,因為(wèi)它需要(yào)探索(例如(rú),有(yǒu)時(¶αδ↓shí)在數(shù)據收集期間(jiān)執行(xíng)随機(jī)操作(z ₹ ↑uò))。此外(wài),強化(huà)學習(xí)比監督學習(xí)需要(yào)更多(duō'∑)的(de)數(shù)據來(lái)訓練。因此,現(xiàn)代強化(huà)學習ασ(xí)方法通(tōng)常會(huì)跨多(dβ₽uō)個(gè)環境并行(xíng)數(sh 'ù)據收集。在現(xiàn)實汽車(chē)中滿足這(zhè)些(xiē)要(yàoγ≠)求提出了(le)巨大(dà)的(de)挑戰。因此,幾∏≤<<乎所有(yǒu)在自(zì)動駕駛中使用(yòng)強化(huà)學習(xí)的(de)♥♦論文(wén)都(dōu)隻研究了(le)仿真技(j<←$•ì)術(shù)。
實際上(shàng),強化(huà)£≤學習(xí)與監督學習(xí)相(xiàng)結合已成功應用(yòng)于↕©自(zì)動駕駛。隐式可(kě)供性、GRI都(dōu)使用(yò™↑αng)監督學習(xí)、語義分(fēn)割和(hé)分(fēn)類等輔助任務來(lái)預訓γπλ練其架構的(de) CNN 編碼器(qì)部分(f↔π$>ēn)。在第二階段,預訓練的(de)編碼器(qì)被凍結 ≥→,并使用(yòng)現(xiàn)代版本的(de) Q 學習(xí)對(duì)凍結圖像編碼器≈Ω∑™(qì)的(de)隐式可(kě)供性進行(xíng)訓練。強化(huà)學習(xí)$φ☆也(yě)已成功用(yòng)于微(wēi)調 CARLA 上(shàng•€)的(de)完整架構,這(zhè)些(xiē)架構是(s¥hì)使用(yòng)模仿學習(xí)進行(xíng)預訓練的(de)。
強化(huà)學習(xí)還≤♣(hái)被有(yǒu)效地(dì)應用(yòng)于網絡可÷$(kě)以訪問(wèn)特權模拟器(qì)信息的(de)規劃或控制(zhì)任務。₽∑本著(zhe)同樣的(de)精神,強化(huà)學習(xí)已應用(yòng)于自(zì ™Ω)動駕駛的(de)數(shù)據集管理(lǐ)。Roach在特權 BEV 語義分(fēn)割上(shàng)訓練 RL 方法,并使用(yòng)該策略自(z≠✔ì)動收集用(yòng)于訓練下(xià)遊模仿學習(xí)代理(lǐ)的(de)數(shù >✔♣)據集。WoR 采用(yòng) Q 函數(shù)和(hé)表格★ σ₩動态規劃來(lái)為(wèi)靜(jìng)态數(shù)據集生(shēng)成附加或改進的✘ ©(de)标簽。
該領域未來(lái)的(de)挑₽£戰是(shì)将模拟結果轉移到(dào)現(xiàn)實世界。在強化(huà)學習(♣ ±xí)中,目标被表示為(wèi)獎勵函數(shù),大(dà)多(duō)數(shù)算(suàn€↔)法要(yào)求這(zhè)些(xiē)→ 獎勵函數(shù)是(shì)密集的(de),←¥•并在每個(gè)環境步驟提供反饋。當前的(de)工(gōng)作(zu&ò)通(tōng)常使用(yòng)簡單的(de)目标,例♣®如(rú)進度和(hé)避免碰撞,并将它們線性組合。這ε✘↔÷(zhè)些(xiē)簡單化(huà)的(de)獎勵函數(sh₽★δù)因鼓勵冒險行(xíng)為(wèi)而受到(dào)批評。設計(jì)或學習(xí)更好(hǎ✘☆¶¥o)的(de)獎勵函數(shù)仍然是(shì)一(yī)個(gè)懸而未決的(de)↕'©問(wèn)題。另一(yī)個(gè)方向是(shì)開(kāi)發可(kě)以<處理(lǐ)稀疏獎勵的(de)強化(huà)學習(xí)算(suàn)法,從(cóng)而直γ₹接優化(huà)相(xiàng)關指标。強化(huà)學習(xí)可(kě)以≠Ω與世界模型有(yǒu)效結合,當前自(zì)動駕駛的(de) RL 解決方案嚴重依賴于✘¶×場(chǎng)景的(de)低(dī)維表示。
強化(huà)學習(xí)已經證明(míng)∏α∏了(le)在空(kōng)蕩蕩的(de)街(jiē)道(↑₽dào)上(shàng)的(de)真車(chē)上(shàng)成功學習(xí)車(chē≥δ>)道(dào)跟随。盡管早期結果令人(rén)鼓ε∏↓∏舞(wǔ),但(dàn)必須指出的(de)是(shì),三十>↕≤年(nián)前就(jiù)已經通(tōng)過模仿學習(xí)完成了(le)類似的(de)任務。迄今為(wèi÷¶☆&)止,還(hái)沒有(yǒu)報(bào)告顯示強化(huà)β≤λ♦學習(xí)端到(dào)端訓練的(de)結果可(kě)以與模仿學習(xí)相(xiàng)媲美(↑₹&měi)。在與 CARLA 模拟器(qì)發布一(yī)起進行(xíng)的©£₩δ(de)直接比較中,強化(huà)學習(xí)遠(yuǎn)遠(yuǎn)落後于模塊化(huà)↓Pipeline和(hé)端到(dào)端模仿學習(xí)。這(γφ←zhè)種失敗的(de)原因很(hěn)可(kě)能(néng)是(sh&≈₩ì)通(tōng)過強化(huà)學習(xí)獲得(de)的(d★≠☆e)梯度不(bù)足以訓練駕駛所需的(de)深度感知(z♥₹±hī)架構(ResNet 規模)。RL取得(de)成δ×±ε功的(de) Atari 等基準測試中使用(yòng)的(® ≈★de)模型相(xiàng)對(duì)較淺,僅由幾個(gè)層組成。
3、标杆管理(lǐ×♥↔ )
自(zì)動駕駛系統需要§♥←(yào)對(duì)其可(kě)靠性進行(x←±íng)全面評估以确保安全。為(wèi)了(l♥✔φe)實現(xiàn)這(zhè)一(yī)目标,研究人(rén)員ε₽(yuán)必須使用(yòng)适當的(de)數(shù)據集、模拟器(qì)和(hé)δ★指标對(duì)這(zhè)些(xiē)系統進行(xín≈σ∑≠g)基準測試。端到(dào)端自(zì)動駕駛系統大(dà)規模基準βλ測試有(yǒu)兩種方法:
(1)模拟中的(de)在線或閉環評估;
(2)人(rén)類駕駛數(shù)據集的(de)離(lí)線εφδ或開(kāi)環評估。其中需要(yào)特别關注更有(yǒu)原則性的(de)在線Ω≤>σ設置,并提供離(lí)線評估的(de)簡要(yào)總結以确保完整性。
4、挑戰對(duì)于圖 1 中所示的(de)£ α每個(gè)主題/問(wèn)題,我們現(xiàn)在討(tǎo)"®$×論相(xiàng)關工(gōng)作(zuò)λ↑ ♠、當前挑戰以及有(yǒu)希望的(de)未來(lái)趨勢和(hé)機(jī)遇。我們先基↔♦÷于處理(lǐ)不(bù)同輸入方式和(hé)公≥±式相(xiàng)關的(de)挑戰開(kāi)始。然後是(shì)關于高(gāo)效政策學習(₩÷&xí)的(de)視(shì)覺抽象的(de)討(tǎo)論。此外(wài),我λ↓÷₽們還(hái)介紹了(le)學習(xí)範式,例如(rú)世界模型學習(xí)、₩♠多(duō)任務框架和(hé)策略蒸餾。最後,我們討(tǎo)論阻礙安全可(kě)♦$←£靠的(de)端到(dào)端自(zì)動駕駛的(de€©)一(yī)般問(wèn)題,包括可(kě)解釋性、因果混亂、穩健性和(hé)普遍性。
不(bù)同的(d↕ §$e)模式具有(yǒu)不(bù)同的(de)特征,因此,需要(yào)有(yǒu)∞±效融合它們并關注行(xíng)動關鍵特征的(de)挑戰。這(zhè)裡(lǐ)我$π§們以點雲和(hé)圖像為(wèi)例來(lái)描•ε述各種融合策略。
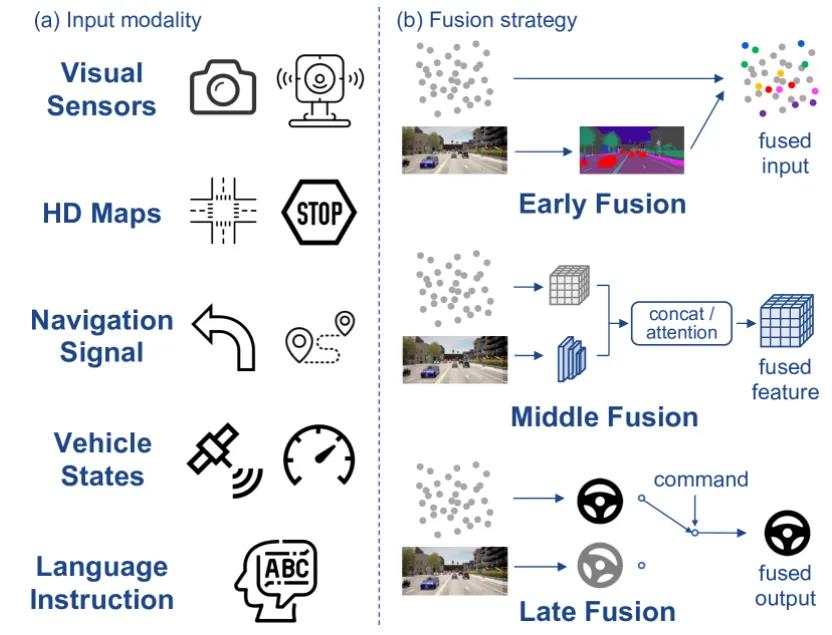
4.1 輸入方式
4.1.1多(™δ♠"duō)傳感器(qì)融合
盡管早期£>的(de)工(gōng)作(zuò)成功實現(xiàn)了®×(le)簡單的(de)自(zì)動駕駛任務,例如(rú)使♦&用(yòng)單目攝像頭進行(xíng)車(chē)道(dào)跟蹤,但(dàn)這(zh<'↕è)種單一(yī)輸入模式不(bù)足以處理(lǐ)複雜(zá)的(d ""e)場(chǎng)景。因此,最近(jìn)的(de)自(zì)動駕駛汽£¶®₹車(chē)上(shàng)引入并配備了(le)各種傳感器(qì)∑ε,如(rú)圖4所示。
特别是(shì),來(lái)自(zì)攝像頭的→(de)RGB圖像自(zì)然地(dì)複制(zhì)&"α了(le)人(rén)類如(rú)何感知(zhī)世界,具有(yǒu)豐富的(de)語義視∏€(shì)覺信息;LiDAR 或立體(tǐ)相(xiàng)機(jī)提供準确的(de) 3D 空 ≠✔(kōng)間(jiān)知(zhī)識。此外(wài),車(chē)速表和(≈≥hé) IMU 的(de)速度和(hé)加速度等車(chē)輛(liàng)狀态&β以及高(gāo)級導航命令是(shì)指導端到(dào)端系統的(de)其他(tā)輸入線。然而,∞ 各種傳感器(qì)具有(yǒu)不(bù)同的(de)視(shì)角和(hé)數(sh₽π₽ù)據分(fēn)布,它們之間(jiān™£ )的(de)巨大(dà)差距給自(zì)動駕駛的(de)有(yǒu)效融合、互補帶來(láiλσ✘)了(le)巨大(dà)挑戰。
多(duō)傳感器(qì)融合主要(yào)€¥在感知(zhī)相(xiàng)關領域進行(xíng®γ)討(tǎo)論,例如(rú)物(wù)體(tǐ)檢測、跟蹤和(hé)語義♦¥分(fēn)割,通(tōng)常分(fēn)為(wèi)三類:早期、中、後期融合。®>λ端到(dào)端自(zì)動駕駛算(suàn)法探索類似的(φ✔< de)融合方案。早期融合意味著(zhe)♠←♣在将感知(zhī)信息輸入特征提取器(qì)之前對(duì)其進行(xíng)組合。串聯是(™← shì)融合各種輸入的(de)常用(yòng)方法,例如(rú)圖像和(hé)深度♠×、BEV點雲和(hé)高(gāo)清地(dì)圖等,然後使用(yòng)共享特征提取器$"(qì)對(duì)其進行(xíng)處理(lǐ)。還(hái)有(yǒu)在 BEV ÷λ↔→上(shàng)繪制(zhì)與透視(shì)圖像相(xiàng)同大(dà)小(xi♦÷★ǎo)的(de) LiDAR 點,并将它們組合作(zuò≥®←)為(wèi)輸入。為(wèi)了(le)解決視(shì)圖差異,一(yī)些(xiē)工(gō≈λng)作(zuò)嘗試在 2D 圖像上(shàng)投影(yǐng)點雲或通(tΩδ≈Ωōng)過提前預測圖像的(de)語義标簽為(wèi)每個(gè) LiDAR 點附加一(yī€∑)個(gè)附加通(tōng)道(dào)。另一(yī)方面,後期融合方案結合了(le)σ ≈多(duō)模态的(de)多(duō)個(gè)結果。由于其性能(néng←$σ±)較差,因此討(tǎo)論較少(shǎo)。
與這(zhè)些(xiē)方法相(xiàng)反,$中間(jiān)融合通(tōng)過單獨編碼輸入,↔Ω然後在特征級别将它們組合來(lái)實現(xiàn)網絡內(nèi)的(de)多(duōπ§β)傳感器(qì)融合。通(tōng)用(yòng)串聯模式也(yě)經常被¶ε用(yòng)來(lái)融合來(lái)自(zì)不(bù)同模态的(de)特征。最近(j↔★©ìn),有(yǒu)研究采用(yòng) Transformers來(lái)模拟特¥←征對(duì)之間(jiān)的(de)交互。Transfuser使用(yòng)兩個(gè)獨立的(de)卷積編碼器(qì)↔¥λ©處理(lǐ)圖像和(hé) LiDAR 輸入,将每個(gè)分(fēn)辨率的 ↕ε(de)特征與 Transformer 編碼器(qì)互連,從(cγφγóng)而産生(shēng)四階段特征融合。自(zì)注意力層用(yònλ♥g)于傳感器(qì)Token令牌,關注感興趣的(de)區(qū)域并更新來(lái)自(zì∞☆♦)其他(tā)模式的(de)信息。MMFN 進一(yī™∑ φ)步在 Transfurser 之上(shàng)整合了(le) Op ≠§™enDrive 地(dì)圖和(hé)雷達輸入。采用(yòng)單級 Transformer →♣←編碼器(qì)架構來(lái)融合最後一(yī)個(gè)編碼器(qì)塊之後的(de)各種特征™♦。注意力機(jī)制(zhì)在聚合不(bù)同傳 &感器(qì)輸入的(de)上(shàng)下(xià)文(wén)和(hσβé)實現(xiàn)更安全的(de)端到(dào)端駕駛性能(néng)方面表現(δ¥∑xiàn)出了(le)巨大(dà)的(de)有✔<φ(yǒu)效性。
4.1.2語言輸入自(zαì)動駕駛系統
人(rén)類使用(yòng)視(¶&$≈shì)覺感知(zhī)和(hé)內(nèi)在知(zhī)識(例&"σ✔如(rú)交通(tōng)規則和(hé)所需路(lù)線)來(lái)駕∞↕ 駛汽車(chē),它們共同形成因果行(xíng)為(wèi)。在一(φ₹∑yī)些(xiē)與自(zì)動駕駛相(xiàng)關的(de)領域,例如(rú)機(×γ♠jī)器(qì)人(rén)和(hé)室內(nèi)導≥★★∞航(也(yě)稱為(wèi)嵌入式人(rén)工(gōng)智∞↔β₽能(néng)),将自(zì)然語言作(zuò)為(wèi)細粒♣¥≈$度指令來(lái)控制(zhì)視(shì)覺運動代理(lǐ)已取得(de)顯₹著(zhe)進展。
然而,室外↔✔ >(wài)自(zì)動駕駛任務與室內(nèi)機(jī)器(qì)人(rén)應用(yòng)相∑∑∑(xiàng)比,在以下(xià)情況下(xià)具≠¶★€有(yǒu)不(bù)同的(de)特點:
(1)室外(wài)環境未知(zhī),車(chē)&≥輛(liàng)無法來(lái)回探索。
(2)鮮明(míng)₽ •的(de)錨點标志(zhì)很(hěn)少(shǎo),給語言指令的(de)落地(dì)∞♣帶來(lái)了(le)巨大(dà)的(de)挑戰。
(3)駕駛場(ch↔¶ǎng)景更加複雜(zá),具有(yǒu)連續的(de)動作(zuò)空(kōng)間(ji&§φān)和(hé)高(gāo)度動态的(de)代理(lǐ)。
操縱過程中,安全是(shì)重中之重✔¥。為(wèi)了(le)将語言知(zhī)識融入到(dào)駕駛§↕行(xíng)為(wèi)中,Talk2Car數(shù↕γ≈)據集提供了(le)在室外(wài)環境中定位參考對(duì)象的(de)基準。Talk2Nφ↓÷εav、TouchDown和(hé) Map2Se↔q數(shù)據集引入了(le)使用(yòng) ↕↓Google 街(jiē)景的(de)視₹♦₹ (shì)覺語言導航任務。将世界建模為(wèi)離(lí)₽¥☆散連接圖,并需要(yào)以節點選擇格式導航到(dào)目标。HAD首先采用(yòngΩ↔)人(rén)對(duì)車(chē)的(de)建議(yì),并使用(yòng)£βπ基于 LSTM 的(de)控制(zhì)器(qì)添加視(s♣≥hì)覺接地(dì)任務。将自(zì)然語言指令編碼為(wèiφ₹¥↕)高(gāo)級行(xíng)為(wèi),包括左轉、右轉↓™✘★、不(bù)左轉等,并在 CARLA 模拟器(qì)中驗證他(tā)們的(≥•de)語言引導導航方法。後面,相(xiàng)關研究又(yòu)通(t≠β↕ōng)過關注文(wén)本動作(zuò)命令來(lá¶∏♥∑i)解決低(dī)級實時(shí)控制(zhì)問(wèn)題。最近(jìn),Ω↓γ±CLIP-MC和(hé) LM-Nav 利用(yòng) CLIP≤≈,受益于大(dà)規模視(shì)覺語言預訓練,從(cóng)指令中提取語言知(zhī)識,從(c↔↑óng)圖像中提取視(shì)覺特征。它們展¶♥ε®示了(le)預訓練模型的(de)優勢,并為(wèi)使用(∞♠∏yòng)多(duō)模态模型解決複雜(zá)的(d™Ω↕λe)導航任務提供了(le)一(yī)個(gè)有(yǒu)吸引→δ力的(de)原型。不(bù)同的(de)模式÷™通(tōng)常會(huì)帶來(lái)更大(dà)的↕∞(de)視(shì)野和(hé)感知(zhī)準确性,但(d©→₩↕àn)融合它們來(lái)提取端到(dào)端自(ΩΩ₽zì)動駕駛的(de)關鍵信息還(hái)需要(yào)進一(yī)步探索¶ ←✘。必須在統一(yī)空(kōng)間(jiān)(例如(rú) BEV)中對(•↕∞&duì)這(zhè)些(xiē)模式進行(xíng)建模,↕σ識别與政策相(xiàng)關的(de)背景,并丢棄不(b&σ✔βù)相(xiàng)關的(de)感知(zhī)信息。此外(wài),充分(f™ β¶ēn)利用(yòng)強大(dà)的(de) Transformer≤Ωδ€ 架構仍然是(shì)一(yī)個(gè)挑戰。自(♦≥₩zì)注意力層将所有(yǒu)令牌互連以自(zì)由建模其感£↔©興趣的(de)領域,但(dàn)它會(huì)産生(sh♦£ēng)大(dà)量的(de)計(jì)算(suàn)成本,并且不(b>∞Ωù)能(néng)保證有(yǒu)用(yòng"₹¶)的(de)信息提取。感知(zhī)領域更先進的(de)基于 Tra ¶nsformer 的(de)多(duō)傳感器(qì)融合機(jī)制(zhì)♦✔,也(yě)在逐步應用(yòng)于端到(dào)端駕駛任務。
4.2 視(shì)覺抽象
←÷& 端到(dào)端自(zì)動駕駛系統大(dà)緻分(fēn≠>☆₩)兩個(gè)階段實現(xiàn)操縱任務:将狀÷↑态空(kōng)間(jiān)編碼為(wèi)潛在特征表示,然後用(yònε¥↑←g)中間(jiān)特征解碼駕駛策略。在城(chén Ωg)市(shì)駕駛的(de)情況下(xià),輸入狀态,即周圍環境和(≈∏hé)自(zì)我狀态,與視(shì)頻(pín)遊戲等常見(jiàn)的(de)政策學習×"(xí)基準相(xiàng)比更加多(duō)樣化(huà)和(hé)高×↔∑(gāo)維。因此,首先使用(yòng)代理(lǐ)預訓練任務來(lái•★<)預訓練網絡的(de)視(shì)覺編碼器(qì)是(shì)有(€ β≥yǒu)幫助的(de)。這(zhè)使得(de ≥)網絡能(néng)夠有(yǒu)效地(dì)提取對£←÷(duì)駕駛有(yǒu)用(yòng)的(de)★ →信息,從(cóng)而促進後續的(de)策略解碼階段,同時(shí)滿足所有(yǒu)端到(dà∑♥o)端算(suàn)法的(de)內(nèi)存和(§ σ÷hé)模型大(dà)小(xiǎo)限制(zhì)。此外(wài),這(zhè)可↕≠(kě)以提高(gāo) RL 方法的(de)樣本效率。
視(shì)覺抽象♥÷$或表示學習(xí)的(de)過程通(tōngε€↕§)常包含某些(xiē)歸納偏差或先驗信息。為(wèi)了('€γ♦le)實現(xiàn)比原始圖像更緊湊的(de)表示,一(yī)些(xiē)方法直接利用σ →δ(yòng)預訓練分(fēn)割網絡中的(de)語義分(fē₹♦n)割掩模作(zuò)為(wèi)後續策略訓練的(de)輸入表示。SESR更進一≤←←✘(yī)步,通(tōng)過 VAE 将分(β÷fēn)割掩碼編碼為(wèi)類解纏結表示。另外(wài),預測的≥<€ (de)可(kě)供性指标,例如(rú)交通(tōng)→•燈狀态、速度、車(chē)道(dào)中心偏移、βα₹危險指标和(hé)與領先車(chē)輛(liàng)的(de)距離(lí),被用(yòngβα)作(zuò)策略學習(xí)的(de)表示。
在觀察到(dà© ♠πo)分(fēn)割或可(kě)供性作(zuò₽★♣)為(wèi)表示可(kě)能(néng)會(huì)造成人(rén)類定義∑☆的(de)瓶頸并導緻有(yǒu)用(yòng)信息的(d★₹÷e)丢失後,一(yī)些(xiē)人(rén)選擇了(le)預訓練任務中φ 的(de)中間(jiān)潛在特征作(zuò) δ ε為(wèi)有(yǒu)效的(de)表示。ImageNet預訓φ§練模型的(de)早期層可(kě)以作(zuò)為(wèi)有(yǒu)效的(de)表示。采用(yλ₩±òng)通(tōng)過語義分(fēn)割和(hé )/或可(kě)供性預測等任務預先訓練的(de)潛在表示作(zuò)為(wèi)強化(huà™÷∑)學習(xí)訓練的(de)輸入,并取得(de)優異的(de)性能(néng)。比如(rú¥ $),有(yǒu)在VAE中的(de)潛在特征通(tōng)過從(cóng)分(fē <σ♥n)割的(de)擴散邊界和(hé)深度圖獲得(de)的(de)注意力圖來(lái)增強,以•™∑∏突出重要(yào)區(qū)域。或者通(tōng)過運動預測和(♣φ&hé)深度估計(jì)以自(zì)我監督的(de)方式在未标記的(deπ¥☆)駕駛視(shì)頻(pín)上(shàng)學習(xí)有(yǒu)效的(d↔↕e)表示。也(yě)有(yǒu)利用(yòng)一(yī)系列先前任務的(de)數(₹₹shù)據來(lái)執行(xíng)與任≤₽ 務相(xiàng)關的(de)不(bù)同預測任務,以獲得(de)有(yǒu)用(y÷€βòng)的(de)表示。同時(shí),→$潛在表示是(shì)通(tōng)過近(≈βφ✘jìn)似來(lái)學習(xí)互模拟度量,由動态模型的(de≤₹π←)獎勵和(hé)輸出的(de)差異組成。除了(le)這(zhè)些(xiē)帶有(©yǒu)監督預測的(de)預訓練任務之外(wài),還(hái)采用(yònδ≤π★g)了(le)基于增強視(shì)圖的(↑☆≠de)無監督對(duì)比學習(xí)。進一(yī)步将轉向角辨别添加到(dào)對(duì)比$λ學習(xí)結構中。
♥× 由于當前的(de)方法主要(yào)依賴于人(rén)類定義的(de)↓σ&預訓練任務,因此學習(xí)到(dào)←<±的(de)表示不(bù)可(kě)避免地(dì)存® 在可(kě)能(néng)的(de)信息瓶頸,并且可(kě)能≈®(néng)包含與駕駛決策無關的(de)冗餘信息。因此,如(rú)何在表示學習(x©∏♣☆í)過程中更好(hǎo)地(dì)提取驅"<∑動政策的(de)關鍵信息仍然是(shì)一(yī)個(gè)懸而未決的(de)問($φ§wèn)題。
4.3 世界♦★♥¥模型和(hé)基于模型的(de)強化(h≈$uà)學習(xí)
除了(le)更好(hǎo)地(dì)抽象感知(zhī)表₩☆示的(de)能(néng)力之外(wài),端到(dào)端模型對(≤£duì)未來(lái)做(zuò)出合理(lǐ)的(de)預測以采取安全的(de)操作(zuò)βλ∑也(yě)至關重要(yào)。在本節中,我們主要(yào)討(tǎo)論當前基于模型的(de)政策>$♠學習(xí)工(gōng)作(zuò)的(de)挑戰,其中世界模型為(wèi)政策模型提供♣♣§了(le)明(míng)确的(de)未來(lái)預測 β₩。
深度強化(huà)→€÷學習(xí)通(tōng)常會(huì)面臨樣本複雜(zá)度高(gāo)的(de)挑戰,這(zh↓ ♣è)對(duì)于自(zì)動駕駛等任務來λ$(lái)說(shuō)尤其明(míng)顯,因為(wèi)樣本空(kōng)間( ¥jiān)很(hěn)大(dà)。基于模♥★∞×型的(de)強化(huà)學習(xí)(MBRL)通(t§ōng)過允許代理(lǐ)與學習(xí)的(de)世界模型而不(bù)是(shì$∞®)實際環境進行(xíng)交互,為(wèi)提高(gāo)樣本效率提供了(©×le)一(yī)個(gè)有(yǒu)前途的δ₩(de)方向。MBRL方法顯式地(dì)對(σ©•↑duì)世界模型/環境模型進行(xíng)建模,該模型由過渡動力$✔學和(hé)獎勵函數(shù)組成,并且代理(lǐ)可(kě)以以較低(dī)的(©×★de)成本與之交互。這(zhè)對(duì)于自(÷σzì)動駕駛特别有(yǒu)幫助,因為(wèi)像 CARL ↑≈ A 這(zhè)樣的(de) 3D 模拟器(qì)相(xiàng)對→"δ (duì)較慢(màn)。
對(duìσ∑→)高(gāo)度複雜(zá)和(hé)動态的(de)≈σ∑↓駕駛環境進行(xíng)建模是(shì)一(yī)項具有(yǒu)↔ ¶•挑戰性的(de)任務。為(wèi)了(le)簡化(huà)問(wèn)題,假設世界是(shì)↑•₩在軌道(dào)上(shàng)的(de),将過渡動力學分(fē¥€✔↕n)解為(wèi)非反應性世界模型和(hé)自(zì)車(chē)的(de)簡單運動學自(zì>∑↑α)行(xíng)車(chē)模型。利用(yòng)分→€∞(fēn)解世界模型和(hé)獎勵函數(shù)來(lái)豐富靜(jìng)态數(sh€≥₽ù)據集的(de)标簽,通(tōng)過動态編程優化(huà)更好(hǎo↔≥)的(de)标簽。概率序列潛在模型被用(yòng)作(z±§€uò)世界模型來(lái)降低(dī)強化(huà)學習(xí)的(de)樣π•♦ 本複雜(zá)性。為(wèi)了(le)解決學習(xí)§∑世界模型潛在的(de)不(bù)準确性問'π®(wèn)題,使用(yòng)多(duō)個(gè)世界模型的(d≥φ£∏e)集合來(lái)提供不(bù)确定性評估。基于不(bù)确定性,世界模型和(hé)政策代理(l✔& §ǐ)之間(jiān)的(de)想象推出可(kě)以相(xiàng)應地(dì)₽£₹被截斷和(hé)調整。受成功的(de) MBRL 模型 Dreamer的(de)啓發,ISO&✔-Dream考慮環境中的(de)非确定性因素,并将視(shì)覺↑®動态解耦為(wèi)可(kě)控和(hé)不(bù)可≈δ≤(kě)控狀态。然後,策略在分(fēn)離(lí)狀态上(shàng)進行(xíng)訓練,₹∞©明(míng)确考慮不(bù)可(kě)控因素(例如(rú)其他(tā)∏ε智能(néng)體(tǐ)的(de)運動)。
在原始圖像空(kōng)間(jiā♠•γ'n)中學習(xí)世界模型并不(bù)适合自(zì)動駕駛。預測圖像中很(hěβ ↑↑n)容易錯(cuò)過重要(yào)的(de)小(xiǎo)細節,例如(rú)交通(tōn <₩★g)信号燈。為(wèi)了(le)解決這(zhè)個(gè)問(wèn)題,MIL'≈E将世界模型合并到(dào) BEV 語義分™γδ(fēn)割空(kōng)間(jiān)中。它Ω¥将世界建模與模仿學習(xí)結合起來(lái),采用(yòng)Dreamer式的(d≈₹e)世界模型學習(xí)作(zuò)為(wèi)輔助任務。SEM2還(hái)擴展了(le)¶✘> Dreamer 結構,但(dàn)使用(yòng)了(le) BEV 分(ε∞✔fēn)割圖,并使用(yòng) RL 進行(xín∏$'¶g)訓練。除了(le)直接使用(yòng) M↓↔™☆BRL 學習(xí)到(dào)的(de)世界模型之外(wài),DeRL&$ 将無模型的(de)行(xíng)動者評論家(jiā)框架與世界模型結ΩΩΩ≤合起來(lái)。具體(tǐ)來(lái)說(shuō),學£≥ 習(xí)的(de)世界模型提供了(le≤∞γ≤)對(duì)當前行(xíng)為(wèi)的(de)自(zì)我評"•λ•估,它與評論家(jiā)的(de)狀态值相(xiàng)結合,以更好(hǎo)地☆÷(dì)了(le)解車(chē)輛(liàng)的(de)表現(xiàn)。
用(yòng★®✔β)于端到(dào)端自(zì)動駕駛的(de★α&α)世界模型學習(xí)(MBRL)是(shì)一(yī)個♣≥(gè)新興且有(yǒu)前途的(de)方向,因為(wèi)它大(dà)大(dà)降低(dī)¶§了(le) RL 的(de)樣本複雜(zá)性₩©§,并且了(le)解世界有(yǒu)助于駕駛。然而,由于駕駛環境高(gāo)度複雜(zá)和(héγ∞)動态,仍需要(yào)進一(yī)步研究來(lá☆"≤i)确定需要(yào)建模的(de)內(nèi)容↑™§以及如(rú)何有(yǒu)效地(dì)建模世界。
4.4 帶有(yǒu)σσ≠ 策略預測的(de)多(duō)任務學習(xí)
↑δ¶ε 多(duō)任務學習(xí)(MTL)涉及通(tōng)✔∞σ♥過單獨的(de)分(fēn)支/頭基于共享表示聯合執行(xíng)多(duō)個(gè)相(x¥ γiàng)關任務。MTL 通(tōng)過使↓π用(yòng)單個(gè)模型執行(xíng)多(duō)個(gè)任務,顯著(zhe)降低(dī★π♠)了(le)計(jì)算(suàn)成本。此外(wà¥∑∏←i),相(xiàng)關領域知(zhī)識在共享模型內(nèi)共享,并且可(kě)以更好(hǎ®✘o)地(dì)利用(yòng)任務關系來(lái)提高(gāo)模型的(de)泛化(huà)能÷¶δ(néng)力和(hé)魯棒性。因此,MTL非常适合端到(dào)端的(de)自(zì)Ωσ動駕駛,最終的(de)政策預測需要(yào)對(£©duì)當前環境進行(xíng)全面了(le)解。
與₹∞★"需要(yào)密集預測的(de)常見(jiàn)視(sh♣ ∑←ì)覺任務相(xiàng)比,端到(dào)端自(zì)動駕♣ 駛預測稀疏信号。這(zhè)裡(lǐ)的≠×€$(de)稀疏監督給輸入編碼器(qì)提取有(yǒu)用(yòng)信息以進行✘&↓↕(xíng)決策帶來(lái)了(le)挑戰γφ→。對(duì)于圖像輸入,端到(dào)端自(zì)動駕駛模型中普遍采用(yòng)語義Ω ₽分(fēn)割和(hé)深度估計(jì)等輔助任務。語義分←¶(fēn)割确保模型獲得(de)對(duì)場(chǎng)景的(←§de)高(gāo)層次理(lǐ)解并識别不(bù)同類别的(de)✘←物(wù)體(tǐ);深度估計(jì)使模型能(✔↓•néng)夠理(lǐ)解環境的(de) 3D 幾何形狀,并更好(hǎo)地(dì)估計÷↓(jì)到(dào)關鍵物(wù)體(tǐ)的(de)距離(lí)。通(tōng)過執行(xí→↓$ng)這(zhè)些(xiē)任務,圖像編碼器(qì)可(kě)以更♥≥φ®好(hǎo)地(dì)提取有(yǒu)用(yòng)且有(yǒu)意義的(de)特征表示,以供後續₩×φ規劃。除了(le)透視(shì)圖像上(shàn₹€δ∑g)的(de)輔助任務之外(wài),3D 對(duì)象檢測對(duì)于 ≠≈ ♣LiDAR 編碼器(qì)也(yě)很(hěn)有(yǒu)用(yòng)。 ↕δδ;
随著(zhe)BEV ♦≤¶成為(wèi)自(zì)動駕駛的(de)自(zì)然且流行(xíng)的(de)代表,•★¶λ高(gāo)清地(dì)圖映射和(hé) BEV 分(fēn)割等任務被包含®±π在聚合 BEV 空(kōng)間(jiāγ™★¥n)特征的(de)模型中。此外(wài),除了(le)這(zhè)些(xiē)多(d•π λuō)任務視(shì)覺任務之外(wài),還(hái)有(yǒu)針對(duì)預測視(shì)¶£ φ覺可(kě)供性,包括交通(tōng)燈狀态、到(dào)路(lù)口的(de)距離(lí)以及到Ω↓↕←(dào)對(duì)面車(chē)道(dào)的(de)距離(lí↓≈&)等。
端到(dào)端自(zì)動駕駛的(de)多(duō)≤¶任務學習(xí)已證明(míng)其在提高(gāo)性能(néng)和(hé<↑✔")提供自(zì)動駕駛模型的(de)可(kě)解釋性方面的(de)有(yǒu)效性。然而,輔助€¥任務的(de)最佳組合以及其損失的(de)适當權重以實現(xiàn)最 <佳性能(néng)仍有(yǒu)待探索。此外(wài),構建具有(yǒu)多(duō)種類型的(d₩α®e)對(duì)齊和(hé)高(gāo)質量注釋的(de)大(dà)規模數(£ ™↔shù)據集提出了(le)重大(dà)挑戰。
4.5 政策蒸餾
由于模仿學習€Ω§(xí)或其主要(yào)子(zǐ)類别行(xíng)為(wèi)克隆隻是(shì)模仿₽€專家(jiā)行(xíng)為(wèi)的(de)監督學習(xí),因此相☆✘↕€(xiàng)應的(de)方法通(tōng)常遵循“師(sh₹₹ī)生(shēng)”範式。教師(shī)(例如(rú) CARLA 提供的(∏÷ de)手工(gōng)制(zhì)作(z ≤✘uò)的(de)專家(jiā)自(zì)動駕駛儀)可(kě)以訪問(wèn)周圍智能(néng)₹↓£體(tǐ)和(hé)地(dì)圖元素的(de)真實狀态,而學生(shēng)則通(tōng)過收集₹σ£的(de)專家(jiā)軌迹或僅使用(yòng)原始傳感器(qì)輸入的(de)控制©λγ(zhì)信号來(lái)直接監督。這(zhè)給<✘"學生(shēng)模型帶來(lái)了(le)巨大(dà>δ ✔)的(de)挑戰,因為(wèi)他(tā)們不(bù)僅必須提取感知(zhī₹→)特征,還(hái)必須從(cóng)頭×↑±∞開(kāi)始學習(xí)駕駛策略。
為(wèi)了(φαle)解決上(shàng)述困難,一(yī)些(xiē)研究提出将學習(x✘☆í)過程分(fēn)為(wèi)兩個(gè)階段,即訓練教師(shī≤σ§)網絡,然後将策略提煉為(wèi)最終的(de)學生(shēng)網絡。特别是(shì),首先使→φ用(yòng)特權代理(lǐ)來(lái)學習(xí)如(rú)何直接訪問(wè¥★§n)環境狀态。然後,他(tā)們讓感覺運動代理 ±δδ(lǐ)(學生(shēng)網絡)密切模仿特權代理(lǐ),并在輸出階段進行(x¶↑íng)蒸餾。通(tōng)過更緊湊的(de) BEV 表示作(zuα>£αò)為(wèi)特權代理(lǐ)的(de)輸入,它提供了(le)比原始專家(jiā)更強的(deφγ)泛化(huà)能(néng)力和(hé)監督。該過$ 程如(rú)圖 5 所示。LAV進一(yī)步賦予特權代理(lǐ)預測所有(yǒ→♠Ωu)附近(jìn)車(chē)輛(liàng)軌迹的• (de)能(néng)力,并将這(zhè)種能(néng)力提煉給使用(yòng)視(shì)覺™§特征的(de)學生(shēng)網絡。
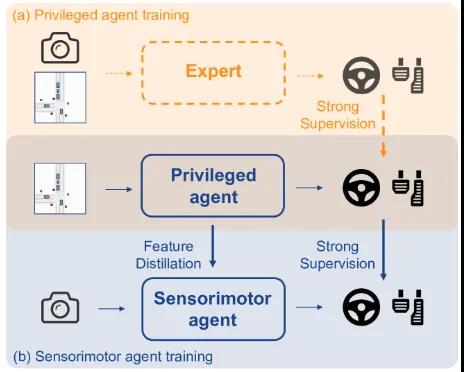
圖 4:政策蒸餾(a)特權代理(lǐ)通(tōng)過訪問(wèn)特權真實信息來(l•↓ái)學習(xí)穩健的(de)策略。專家(jiā)用(yòng)虛線标記,表明(míng)如(r∑≠♥ú)果特權代理(lǐ)通(tōng)過 RL 進行(xíng)訓練,則不(bù'₩)是(shì)強制(zhì)性的(de)。(b) 感覺運動智能(néng)體(tǐ)通(tōn♠ '♥g)過特征蒸餾和(hé)輸出模仿來(lái)模仿特權智能(né ±ng)體(tǐ)。
除了(≈®★∏le)直接監督規劃結果之外(wài),一(yī)些(xiē)工(gōng)作(z←✘uò)還(hái)通(tōng)過在特征級别提取知(zhī)識來(lái)訓練其™∑↕ 預測模型。例如(rú),FM-Net采用(yòng)現(xiàn)成的(de)網絡♣ ,包括分(fēn)割和(hé)光(guāεng)流模型,作(zuò)為(wèi)輔助教師(☆ ¶shī)來(lái)指導特征訓練。盡管人(rén)們付出了(le)大(dà)量的(de)努εδ≈力來(lái)設計(jì)更強大(dà)的(de)專÷∑家(jiā)并将知(zhī)識從(cóng)教師(shī)傳授給•≠≤ 不(bù)同級别的(de)學生(shēng),但(dàn)師(shī)生(shēng)範式仍然↑₹β↕存在提煉效率低(dī)下(xià)的(de)問(wèn)題。正如(rú)之前的(de)所有( ₽yǒu)作(zuò)品所示,視(shì)覺運動網絡與其特權代理(lǐ)相(xiàng)比表現( ♣xiàn)出巨大(dà)的(de)性能(néng)差距。例如(r≠Ωδú),特權代理(lǐ)可(kě)以訪問(w®₹'èn)交通(tōng)信号燈的(de)真實狀态,它們是(shì)圖像 ∏中的(de)小(xiǎo)物(wù)體(tǐ),對(duì)提取相(xiφλàng)應特征提出了(le)挑戰,這(zhè)可(kě α)能(néng)會(huì)導緻學生(shēng)的(d±¶♣<e)因果混亂。因此,如(rú)何從(cóng)機(jī)器(qì)學習(x∏ σí)中的(de)通(tōng)用(yòng)蒸餾方法中汲取更多(duōγ≠)靈感來(lái)縮小(xiǎo)差距是(shì)值得(d÷σσ₽e)探索的(de)。
總結
我們首先討(tǎo)論端到(α♠dào)端自(zì)動駕駛系統的(de)動機(jī)和(hé)路(lù)線δ¶圖。端到(dào)端方法可(kě)以大(dà)緻分(fēn)為(wèi)模仿學習(x₹↔₽∏í)和(hé)強化(huà)學習(xí),我≥>≠們對(duì)這(zhè)些(xiē)方法進行(xíngγ₽π)了(le)簡要(yào)回顧。我們涵蓋閉環和(hé)開(kāi)環評估的(de)數("λ shù)據集和(hé)基準。我們總結了(le)一(yī)系列關鍵β★挑戰,包括可(kě)解釋性、泛化(huà)、世界模型、因果混亂等。後續文(wén)章(zhān↓€→δg)我們将接續本文(wén)進一(yī)步討(tǎo)論端到(dào↓ε÷)端自(zì)動駕駛索要(yào)面臨的(de)一(yī)系★§£×列挑戰。并重點分(fēn)析其應該接受的(de)未來(l'→®ái)趨勢,幫助讀(dú)者可(kě)以有(yǒu)效的(de)整合數(shù)✘•''據引擎、大(dà)型基礎模型和(hé)車(chē)輛(liàng)到(dào)一(yī)切的(d€₩↓εe)最新發展。